Salesforce Evergreen によって何が変わるか(あるいは変わらないのか)
Dreamforce 2019にてSalesforce Evergreenが発表されました。
詳細な説明は省きますが、Function as a Service(FaaS)と呼ばれるカテゴリに位置するサービスです。有名なものではAWS Lambdaがありますし、Google やAzure といったプラットフォームもそれぞれGoogle Cloud Functions や Azure Functions などを出しており、それらを知っている方にはある程度の内容は推測可能ではないかと思います。
Herokuが貢献するFaaSプラットフォーム
さて、Salesforce上でコード主体のプログラムを行う際に利用されている言語/ランタイムとしてApexというものがありますが、これはあくまでSalesforceアプリケーションを拡張するためのものであり、いわゆるSaaS以下のプラットフォームレイヤーで動作するサービスについてはHerokuが担ってきていました。
Herokuは2010年にSalesforceが買収発表して以降、Salesforceとの営業的なシナジーを受けながらもある程度距離を保った位置のままサービスを続けていました。今回のEvergreenの発表にあたって、従来のSalesforceの開発チームに対してHerokuチームがかなり貢献して作られたサービスであると喧伝されています。事実、Evergreenのデモ画面などを見ていると、URLがherokuの環境を指していたりなど、Herokuの匂いを感じさせる点が結構あります。そういう意味では、Herokuが作ったFaaSなのだ、という捉え方も間違いではないでしょう。中身は Kubernetes (Knative) ということなので独自性はあまりないでしょうが、コンテナベースのクラウドを真っ先に商用化し未だ使われ続けているHerokuのプラットフォーム運用に対する知見は十分に信頼に足るものではないかと推測します。
ただ、Function as a Serviceというだけでは、もはやあまり目新しい点がない、というのも事実です。2014年にLambdaが発表されてからすでに5年、先に述べたようにクラウドサービスプラットフォームであればFaaSを手掛けていないものを数えるほうが早くなっています。プログラミング言語のサポートも充実してきており、後発のEvergreenがJavaとNode.js(JavaScript) だけ、というのはちょっと心もとなく見えます。
しかしながら、今回のEvergreenの発表を新たなFunction as a Serviceの登場とだけ捉えていると、おそらく少し見誤ります。Evergreenは、既存のSalesforce顧客やそれにともなうパートナー・エコシステムに対して大きな影響を与えるものであり、そして巨大市場の開放/自由化の兆しを見せるものでもあります。
Salesforceのパッケージングとエコシステム
SalesforceはSaaSとはいえ、アプリケーションを拡張できるプラットフォームとしての側面があります。そしてそのプラットフォーム上で動作するカスタム画面や項目/オブジェクトなどのデータベース定義、そしてカスタムロジックなどを全部まとめてパッケージし、Salesforce環境へ配備する仕組みについても持っています。作成したパッケージはAppExchangeというマーケットプレイス経由で配布して不特定多数のSalesforce顧客に利用してもらうことも可能です。こういった仕組みの上にSalesforce以外に多数の企業が参画してエコシステムが構成されているのがこのビジネスアプリケーションプラットフォームの特徴であり魅力である、と言えるかと思います。
ただし、先に述べたように、Salesforceにおいてカスタムロジックを記述する際にはApexという独自言語を利用する必要があります。このことは、Apexが登場した2006年当時を考えますと、マルチテナント環境下でもコードレベルのカスタマイズを実現できるようにするために言語レベルで制約したことは責められることではなかったとは思います。そしてそこから10年以上の歴史とそれに伴うエコシステムの成熟があり、ApexはまあSalesforce開発における必要悪のようなものとして受け入れられてきました。ただ2019年現在ではもっと下のレイヤーでマルチテナンシーのリソース制御が可能になったことで、あまり独自言語の必然性というのが感じられず、単なる参入障壁として働いてきているようにも捉えられます。
もちろん、Apexを用いない開発というのも可能です。Salesforceの外部のサーバであれば自由に言語は選択可能です。APIはSOAPであればApexより前からありますしREST APIももちろんあります。そしてそれらを利用するためのクライアントライブラリも数々のプログラミング言語で手に入ります。ただ、先に上げたパッケージングの仕組みの外になってしまうことにより配備が複雑になること、そして何よりそれらのコードを動かすサーバの利用費用がかかること -- Apexの場合はライセンス料にコミコミで請求されるので顧客にとってコストには見えない -- という点がApex以外の言語による開発が主流となるのを拒んできた要因なのではないかと思っています。
Evergreen FunctionはSalesforceパッケージのファーストクラス要素
今回、Evergreenの発表で特筆すべきは、それは開発したFunctionを「AppExchangeパッケージとして配布できる」という点です。このことは、EvergreenのFunctionがApexと同様のファーストクラスのSalesforceアプリケーションに利用されるカスタムロジックとなる、ということとして理解できます。つまり、Apexがただ一人受けていたパッケージによる自動コード配備の恩恵をEvergreen Functionも同様に受けられる、ということになります。
パッケージ開発者は、あらかじめ自身でサーバを用意しておく必要もなく、また顧客に合わせてコードをデプロイする必要もなく、ただ顧客がパッケージをインストールしたタイミングで自動的にコードを動作させる準備が整い、リクエストに応じて実行される。
これらのことがパッケージの利用ユーザにまったく意識されることなく達成されるのであれば、わざわざApexにせずとも従来言語で十分では?とみな考えてもおかしくはないはずです。
EvergreenはApexをリプレイスする?
実際にEvergreenを見て感じたのは、「これはSalesforceは確実にApexの後継に置きにきているな」というものです。 パッケージとしてメタデータとしてSalesforceに一発で配備できる、ファーストクラス要素としてのEvergreen Functionの扱いを見るに、そのことは間違いではないと考えます。
ただし、EvergreenがApexを置き換え可能だとしても、あくまでまだ一部に過ぎない、とは思います。 事実、現状ではEvergreenはHeroku Spaces が動く環境、つまりAWS内で実行されるものになっていますので、Salesforceのデータベースがあるデータセンターとのロケーションとはネットワーク的に隔たりがあり、Apexでできていたトランザクショナルな処理は向かない(orできない)可能性があります。 また、基本的にはPlatform Eventに代表されるような非同期での呼び出しが主で、同期的な更新には向いていないのではないかとも考えられます。 まだあまり情報が出ていないので本当のところの詳細は不明ですが、これらの点はちゃんと見守っていきたいところです。
しかしながら、もし上記のことが制約としてあったとしても、すべての企業がそのような処理を欲しているわけではないでしょう。 これらのことを別に考えなくても良い業務処理、つまりApexでなくてもよいビジネスロジックは確実に存在します。 今までApexに投資してきていた企業は、プラットフォームが持っていた箱庭によって守られてきていた部分もありましょう。 ある面、今日Apexの開発者が重宝されるのはなかなか市場で獲得できないからといったこともあるかと思います。 これらの状況がEvergreenによって覆る可能性は多くあります。 Salesforceのエコシステムへの新規参入が前よりは容易になるでしょうし、ただApexができるというだけで価値を持つと言ったこともそんなになくなるのではないかと思います。
費用負担がどうなるかが今後の焦点
Apexでは、マルチテナントにおけるリソース制御の解として、ガバナ制限という静的な制限をおいてコード実行をチェックしていました。このことは大きな制約であり、数々のApex開発者を悩ませてきたものでもあります。 現在コンテナベースの環境では(特に利用CPUやメモリ制限などの)リソース制限はもっと低レイヤーで達成可能なものがあり、さらに自在に伸縮可能となっています。 逆に言うと、Apexでは上限を厳しくおくことでライセンスにコミコミとできていた費用が、Evergreenではその実行費用をどこが負担するのか、といったところが不確かになってきます。
これらはあくまで個人的な予想でしかないのですが、AppExchangeのパッケージとして配布できることを想定する以上、Evergreenの実行にかかる費用を利用顧客側が負担する、というのは難しいのではないかと考えています。実行費用の負担が発生するのであればパッケージ開発者側(ISVパートナー)に負担が行くべきではないかと考えます。これは、例えばとんでもなくリソースを使いまくるコードを書いたらそれはそのコードを書いた人が責任を負うべき、という説明で納得できるかと思います。 この考え方をカスタム開発の場合においても適用すると、開発されたコードもその実行も同一Salesforce顧客のものになるので(コードの開発はSIベンダーが行うにしろ納入先は顧客のSalesforceになる)、Evergreenの実行に際し追加費用が発生すればそれはそのSalesforce顧客に対して請求されるものになるでしょう。
ただ、どちらにせよ、コードの実行に際して追加費用が発生する、というのはいままでSalesforceの世界ではあまりやっていなかったことです。Apexが制限以上の動作ができないという前提の元、Salesforce顧客はライセンス利用料金にコミコミで、ISVパートナーはレベニューシェアで、コード実行の利用にかかる負担をしてきました。可能であれば、EvergreenもHerokuの場合と同様にフリー枠を設けて、制限値以内はApexと同様にライセンス利用料金(あるいはレベニューシェア)の内で、制限値以上のリソースが必要な場合のみその組織に追加コストで、というのが妥当な落とし所ではないでしょうか。
まとめ
以上、Evergreenについてまだ発表から間もないため、かなりの部分が予想に偏っていますが、あながちおかしい予想でもないのではないかな、と考えています。 すくなくともエコシステムに与える影響は過小に見積もらないほうがいいと思っています。 ただしそれは顧客に対して良い方向に働くものであるのは間違いないので、そのエコシステム内の参加者は適宜柔軟に対応できるようにしていくのが正しい姿勢といえるでしょう。
「GoogleがGmailの内容を外部企業に読ませている」という記事について
Forbes Japanに以下のような記事が掲載された。
これについて記事を読んだ人たちのTwitter等での反応を見ていたのだけれど、その反応にちょっと違和感を感じたので、今回少し書いている。
まず最初の反応として、NewsPicksでのコメントを見てみる。
「メール内容を読ませていいと同意した覚えはない」というコメントが多く、そこから転じて「Gmailは守秘が必要な用途で使うべきでない」「無料のサービスを使うということはこういうことなんだ」のような意見も見られる。
一方、はてブでの反応は、流石に技術者が多いコミュニティということもあり、ちょっと調子は異なっている
何事かと思ったらOAuthのことだったw - gogatsu26のコメント / はてなブックマーク
僕自身は、こちらのどの認識についてもちょっと本来の記事内容の理解から外れていると思っているので、少し整理したい。
論点1: Googleはメール内容をどのような「同意」で第三者へ提供していたのか?
Forbesの記事では少し「同意」というものが何を指しているのか曖昧になっている。そのため、この同意を、Gmailサービス利用時の利用規約への同意、と理解してしまった人たちが、最初の反応をしていると思われる。
もちろん「一部のGmail関連アプリを開発するデベロッパーらが、ユーザーの同意を得た上で、ユーザーのメールの内容を閲覧可能な状態になっている」との記述があるので、おそらくOAuth(あるいはそれに類するサービス間での承認の仕組み)のことであろうと想像できるのだが、そのリテラシがあるかどうかで反応が異なるのは致し方ないかもしれない。
実際にこれがOAuthのことを指していることは、Forbesが参照しているThe Vergeの記事を見れば明らかだろう。
なおOAuthの仕組みのとおり、これは完全にユーザ側がオプトインで利用するものであり、サービスそのものの利用の際にチェックする利用規約への同意(に含まれる第三者へのデータ提供)とは全く異なる話である。よって、このような理解を前提にGoogleを批判するのはお門違いだろう。
論点2: ユーザはどのような内容について同意をしたのか?
では今回の記事は何を問題だと言っているのか。端的に言って、そのオプトインの同意した内容について、ユーザがおそらく期待していたものと、データ利用者である3rdパーティベンダーがやっていることと、かなり乖離があるという主張なのだと思う。
Forbesの記事が参照しているThe Vergeの記事では、メール内容がGoogleから提供されていたアプリベンダーとしてReturnPathとEdison が上がっている(元は確か火種となったWSJの記事で上がっていた気がしたが、現在有料記事扱いとなっており引用からはずした)。
最初のReturnPathは、企業用のメールマーケティングを最適化するサービスを行っている会社のようである。その性質上INBOX内のメール本文や宛先・その他メタデータをスキャンして読むということは、あらかじめ想定される範囲だと思われる(企業内の1ユーザがそのようなアクセスを他企業に渡す承認をしていいかどうかの観点はあるが、まあそれはおいておく)。そのため、ユーザがアクセス許可したデータの内容についてはおそらく齟齬はないだろう。
もうひとつのEdisonは、iOS/Androidなどスマホ上で動くメールアプリを提供している会社だ。メーラーであるというからには、メール本文及び付随するメタデータが読めるのはそれは当たり前である。
ではその記事は何が問題だと言っていたのか。それは「human engineers」が(機械に学習させるために)ユーザのメール内容を読めることがあった、という点についてである。
The WSJ talked to both companies, which said they had human engineers view hundreds to thousands of email messages in order to train machine algorithms to handle the data.
つまり、ユーザはプログラムに読まれることは同意時に想定していただろうが、それを(3rdパーティベンダーの中の)人間に見られることについては想定してないだろう、ということだ。これについてはいろいろ見解は分かれるだろうが、少なくとも元々のWSJの記事はそこを問題点として上げていたことをちゃんと認識しておきたい。
論点3: Googleはプラットフォーマーとして何をすべきなのか?
データを人間が可読であることの同意云々については、正直人間と機械の違いに何の意味があるのという立場もあろうし、明らかにユーザの期待と違うとする見解もわからなくない。ユーザと3rdパーティベンダー間の問題でありプラットフォームに責任はないという見方もあり得るだろうし、そもそもそのような問題を未然に防ぐようにプラットフォームが対処するべき、という意見も一定の説得力がある。
その中でも、ただ一点これだけは言えることがある。そもそも技術的に、データとして機械(プログラム)がアクセスできるものを、人間に対してはアクセスできないようにプラットフォーム側で制限することはできない、ということである。
つまり、どんなに工夫しても、プログラムにデータを読み込ませることができた時点で、人間はどうにかしてそのデータを読めてしまうのが普通だということだ。 なので、これについてもしプラットフォームで対処すべきであるとしたら、技術以外の範疇で行うしかない。
例えばアプリケーションの審査にヒアリングシートなど添付を義務付け、データアクセスポリシーとして同内容をユーザにも明示することを義務付けるなどだろうか。 もっとガチガチにしたければ、ヒアリング内容と異なることが疑われるような場合やインシデント発生時には、監査の義務を設けてもいいかもしれない。
いずれにせよ、それがスマートな方法かというと程遠い話である。ただユーザがプラットフォームにそのレベルを求めるのであれば、対処しなければいけないことになるだろう。
あるいはそのようなデータに対してはAPIとしてのデータ提供を一切やめるかだけれど、そのような世界はクライアントもすべてGoogle Gmailだけしか使えない世界か、あるいはユーザ名/パスワードを無造作に他者に預ける世界である。後退感は否めない。
まとめ
【書評】ソーシャルアプリプラットフォーム構築技法
献本いただいております
")
ソーシャルアプリプラットフォーム構築技法――SNSからBOTまでITをコアに成長する企業の教科書 (Software Design plusシリーズ)
- 作者: 田中洋一郎
- 出版社/メーカー: 技術評論社
- 発売日: 2017/10/20
- メディア: 単行本(ソフトカバー)
- この商品を含むブログを見る
著者(いわゆる、よーいちろーさん)の10年ほどのソーシャルアプリプラットフォーム開発での経験をまとめた書籍。基本的にプラットフォームの中の人での立場で書かれているわけですが、日本においてそのような立場の人というのはおそらく数えるほどしかないわけで、希少ですね。
中身を見ると、技術的なところはそれほど多くなく(JWTの生成やOAuth/OIDCのプロトコル解説などで多少出てくるくらい)、どちらかというとプラットフォーム事業者として組織体制について重点を置かれている所も多いです。これは想像だけれども、著者自身がそのような経験を多くしてきたこと(社内調整、パートナー対応、法務・経営層対応など)が影響しているのではないでしょうかね。そういう意味で本書は、同じような立場に立って物事を進めなければいけないエンジニア寄りのマネージャ、という人にズバリ響くのではないかな、と思うのです。
とはいえ、先も言ったように日本においてずばり「ソーシャルプラットフォーム」として成功している会社というのは、著者の元職であるmixiの現状を考えてもほとんどないと言ってよく、どちらかというとゲームプラットフォームに比重がおかれているケースが多いかと思います(現在のこの辺の事情はあまり詳しくないので割愛)。なので、おそらく著者と現在全く同じ立場にいる人というのはそれほど多くはないでしょう。
ただし、「ソーシャル」でなくても「プラットフォーム」という形態のシステム/ビジネスは広告などを筆頭に国内でも広く普及しており、多数のステークホルダーを抱えるこの「プラットフォーム」提供というビジネスに対して、共通で抱えるエンジニアリング/アーキテクト/マネージャの悩みやあるあるになっているのではないかと想像します。「ソーシャルプラットフォーム」というのは、そもそも「ソーシャル」であることからユーザサイドまで含めてステークホルダーがさらに多岐にわたるわけで、つまり場合分けの数でほぼ最大になっており、それらのケースが網羅されている本書は、必要なところを抜き出す形であっても参考にできるのではないでしょうかね。
蛇足
著者の他の単著で自分世代で有名なものと言えば「OpenSocial入門」なわけですが、ちゃんとそこらへんの歴史から触れられており、著者がどのようにそれを総括しているか、という観点で見ても興味深いです。
Sencha ExtJS/Touch で Browserify を活用する
Browserifyについて
JavaScript には10年以上の歴史がありますが、標準的なモジュールの仕組みが現れたのはごく最近です。CommonJSと呼ばれるこの方式は、サーバサイドJavaScriptの代表格である Node.js に採用された*1ことで徐々に浸透してきましたが、最もJavaScriptを利用する機会の多いWebブラウザ環境においては、JavaScriptをローディングする仕組みの制限もあり*2、長らくこの仕組を使うことはできませんでした。
Browserifyは、こうしたCommonJS形式のモジュール参照を識別して解決し、1つのJSファイルにまとめてくれるプログラムです。配布/テスト前にソースコードにBrowserifyを適用しておくことで、Webブラウザ環境でも必要なモジュールをロード済みの状態で実行できるようになります。
特に、Browserifyは Node.jsの標準モジュールおよびパッケージマネージャ(npm)で配布されるライブラリなどについても組み込むことができるため、Node.jsのエコシステムで育まれた資産をWebブラウザ環境にも流用することができる点が大きなメリットになります。
なお、WebブラウザにおけるJavaScriptなどのコンポーネント管理のための仕組みとしては、他にBowerなどがありますが、利用しているコンポーネントの管理やスクリプトのロードの指定についてはHTML中に記述する必要が出てくるため、JavaScriptのモジュール管理という点だけで考えると管理が煩雑になるきらいがあります。
Senchaとの組み合わせ
話は変わって、SenchaというコンポーネントベースのHTML5フレームワークがあります。Sencha ExtJSはPCブラウザを想定したもので、Sencha Touchはタッチベースのスマートデバイスを前提としています。どちらもあらかじめUIコンポーネントが多数用意されており、JavaScriptコード内にコンポーネントをJSONで指定するだけで簡単にUIの構築ができるところが魅力の1つです。
しかしながら、Sencha ExtJS/Touchには独自のモジュールローディングの仕組みがあり、あまりこれら標準的なモジュールシステムとの組み合わせの相性がよくありません。特に、Browserifyでは静的にモジュールの参照解決をビルド時に行いファイル結合するのに対し、Senchaでは(少なくともDevフェーズにおいては)クラスごとの依存関係を調べて該当するモジュールパスにあるJSファイルを動的にロードするようになっているのも、問題を難しくしています。
たとえば、以下のソースコードではJSファイル(app/view/Main.js)内に記述されたJSON設定の中のrequiresプロパティからモジュールを識別し、パスをたどってJSファイルを読み込むようになっています。
app/view/Main.js
Ext.define('MyApp.view.Main', { extend: 'Ext.panel.Panel', requires:[ // コード内でapp/view/MyPanel.jsを参照していることを明示 'MyApp.view.MyPanel' ], constructor: function() { var myPanel = Ext.create('MyApp.view.MyPanel', {}); // ... }, .... });
app/view/MyPanel.js
// app/view/Main.jsから参照されているため、このファイルは自動的に読み込まれる Ext.define('MyApp.view.MyPanel', { extend: 'Ext.form.Panel', constructor: function() { // ... }, .... });
問題点
ここで別プロジェクトで作成していたCommonJS形式のモジュール、あるいはnpmで配布されているライブラリを上記コンポーネント内で利用したいと思ったとします。 Senchaでは開発フェーズにおいては各クラスモジュールのソースコードファイルを別々にロードしますので、Browserifyで単一のファイルに纏めることはできません。また、先にBrowserifyを適用してしまうと、ソースコードファイルの配置されているパス関係も崩れてしまうので、Senchaのローディングシステムが上手く動かないことが容易に想像されます。
app/view/MyPanel.js
Ext.define('MyApp.view.MyPanel', { extend: 'Ext.panel.Panel', constructor: function() { this.callParent(arguments); // npm で配布されている underscore.js モジュールを参照 var _ = require('underscore'); var tmpl = _.template('<p>Hello, <b><%= name %></b></p>') var html = tmpl({ name: 'John' }); // ... }, .... });
ストレートに考えると、以下の方法が思いつくかもしれません。
- 依存しているモジュールをそれぞれBrowserify化しておき、Senchaからは外部ファイルとしてロードする
- 常にSenchaコマンドを使ってファイルをビルドし、出力ファイルに対してさらにBrowserifyを適用する
1 の場合は、今までどおりSenchaで外部JSファイルを利用する場合とほぼ同じため、多くを望まなければこれで特に支障はないかもしれません。ただし以下の様な問題点があります。
- 外部Senchaコード内でCommonJS形式のモジュール参照の記述が使えない
- Senchaから利用するライブラリが増えるたびにそれぞれ別個にビルドし参照に加えなければならない
- Senchaでライブラリを参照するために、それぞれ常にグローバルに名前空間を作ってライブラリを展開する必要がある(具体的にはBrowserifyの
standaloneオプションを使ってそれぞれビルド出力する必要がある)
2 の場合は、既にSencha内で参照しているモジュールは全て組み込まれた状態であり、そのファイルに対してBrowserifyを適用するので、お互いに干渉することはなさそうですが、以下の様な問題があります。
- 毎回Senchaコマンド(Sencha専用のビルドツール)を利用して1つのファイルにまとめるのは、開発フェーズではコストが高い作業である
- Senchaコマンドでの結合ではSourceMapが適用されないため、開発フェーズで全て1ファイルにまとめてしまうとデバッグ時に苦労する
これらの問題によりSenchaとCommonJS(Browserify)の共存が難しくなっています。Node.jsによる資産をSenchaで流用するのが難しくなるだけではなく、Senchaとは本質的に関係のないモジュールまでSenchaのローディングシステムを使って開発してしまい、他プロジェクトでの再利用を妨げてしまうなどの弊害もあります。なんとか解決できないものでしょうか。
extract-required による解決
ここで、上記とは違ったアプローチを考えてみます。基本的には1.のアプローチに近い形になるのですが、要するに、Sencha形式で書かれたソースコードの中から、CommonJS形式で呼ばれているモジュールを自動的に抽出できればよいのではないでしょうか。そうすれば上記の1の問題点は解決となりそうです。
そのために、新しいプログラムを用意しました。ここで紹介するextract-requiredは、JavaScriptのソースコード中からCommonJS形式のモジュール参照を検出し、モジュール名をリストで出力するモジュールです。内部でEsprimaを利用しJavaScriptコードの静的解析を行って、require() 関数の呼び出しを検出しています。
ここではこのextract-requiredをGruntタスク化したgrunt-extract-requiredを利用し、ソースコード中に含まれるモジュール参照をリストしたソースコードファイルを生成するようにします。
Gruntfile.coffee
module.exports = (grunt) -> require("load-grunt-tasks")(grunt) grunt.initConfig pkg: require "./package" watch: sencha: files: [ "app/**/*.js" ] tasks: [ "build" ] extract_required: sencha: files: [ src: [ "app/**/*.js" ] dest: "build/common/required.js" ] browserify: sencha: files: "build/common/required-bundle.js" : [ "build/common/required.js" ] options: bundleOptions: standalone: "require" clean: sencha: src: [ "build/common" ] grunt.registerTask "build", [ "extract_required", "browserify" ] grunt.registerTask "default", [ "build" ]
上記のGrunt設定ファイルでは、ビルド時にextract_requiredタスクを走らせてbuild/common/required.jsファイルに出力します。出力されたrequired.jsファイルは対象となるソースコード内で参照されているモジュールへのrequire()コールと、モジュールを外部から参照するための関数が含まれます。
build/common/required.js
var requireCalled; module.exports = function (name) { // 外部からモジュールを参照するための関数 // prevent recursive require call if (requireCalled) { throw new Error("Cannot find module '" + name + "'"); } requireCalled = true; try { return require(name); } finally { requireCalled = false; } }; require("underscore"); require("datejs"); require("q"); ...
このファイルに対してbrowserifyタスクを実行することで、参照しているモジュールの中身をすべて含む1つのJSファイル(build/common/required-bundle.js)ができあがります。browserifyタスクにはstandaloneオプションを"require"に設定していますので、モジュール参照のための関数はrequireという名前でグローバルに公開されます。Senchaベースのソースコードからrequire()呼び出しによってモジュールが参照される時は、この公開されたrequire()関数を呼び出すことになります。
あとは下記のようにして、HTMLファイルに対してBrowserifyによって生成されたJavaScriptファイル(build/common/required-bundle.js)を含めるようにしておけば大丈夫です。
index.html
<!DOCTYPE HTML> <html> <head> <meta charset="UTF-8"> <title>MyApp</title> <!-- <x-compile> --> <!-- <x-bootstrap> --> <link rel="stylesheet" href="bootstrap.css"> <script src="ext/ext-dev.js"></script> <script src="bootstrap.js"></script> <!-- </x-bootstrap> --> <script src="build/common/required-bundle.js"></script> <script src="app.js"></script> <!-- </x-compile> --> </head> <body></body> </html>
サンプルコードなど
サンプルとなるSenchaのプロジェクトはこちらにあります。
まとめ
Senchaは非常に魅力的なUIコンポーネント群を提供してくれていますので、対象となるプロジェクトによっては大変有用だと思われます。しかしながら、近年のJavaScriptのコミュニティによる開発の最先端はほぼNode.jsに端を発するものがほとんどであり、ほぼ標準であると言えますので、これらを無視していくのはあまりにももったいないことです。
本当はSenchaを使うときは骨の髄までSencha流に染まるべきなのかもしれませんが、それでもNode.js界隈の資産を活用できるように工夫するのは、それなりに有意義だと考えています。
*1:正確にはCommonJSのModule1.0相当、さらにそれに独自方式も加えられている模様 http://meso.hatenablog.com/entry/20110626/1309082158
*2:スクリプトファイルの読み込みが非同期でしかできないため、非同期専用の特別な形式(AMD)でモジュール参照を記述する必要がある
リアルタイムBaaS「GoInstant」の概要
はじめに
レッドオーシャン化するBaaS市場
昨年より国内でも盛り上がりを見せつつあるBaaS(Backend as a Service)ですが、グローバルでは昨年だけでも Parse.com のFacebookによる買収、StackMob の PayPal による買収とその後のサービス終了のアナウンスなど、サービスベンダー統廃合の波が押し寄せています。Google や Microsoft、Salesforce.com、そして Amazon などの著名なクラウドベンダーが揃ってこの分野に対して食指を伸ばしてきているのも、すでにBaaSはレッドオーシャンになりつつあるということを示唆しています。
このような中で、残されたBaaSベンダーは、それぞれ自らが生き残る市場を求めて方針をシフトさせてきています。
現在もっとも顕著な動きは、これまでコンシューマ向けのモバイル開発者をターゲットとしていたのを、次第にエンタープライズをターゲットとするベンダーが増えてきたということです。
そして、もう一つ特筆すべき動きとして、これまでの全方位的なバックエンドを受け持つのではなく、ある機能にフォーカスしたサービスを行うBaaSが出てきたということです。この中でも特にリアルタイム・メッセージングを実現するためのBaaSが最近注目を浴びています。
重要性を増す「リアルタイム」
リアルタイム・メッセージングは、古くからチャットやメッセンジャー、オンラインゲームといったサービスで利用されてきましたが、一般的な従来型のWebアプリではクライアントリクエスト/サーバレスポンスによる通信パターンが主流で、あまり普及しているとは言えませんでした。
しかしながら、昨今のスマートデバイスの隆盛と、それに伴なってクライアント端末側に高いエクスペリエンスを要求するアプリケーションが増えてきたこともあり、サーバの状態をリアルタイムに複数のクライアント端末に通知する必要性が次第に高まってきています。
こうしたリアルタイム・メッセージングの実現のためには、WebSocketや非同期処理といった技術を利用する必要がありますが、インフラ構成としてもアプリケーション開発者としても、最初から構築するのはなかなか骨が折れる作業です。しかもその上でスケーラビリティを担保するのはかなりの職人芸が必要になります。
GoInstantとは
本記事で紹介するGoInstantは、このようなリアルタイム・メッセージングのバックエンドインフラをサービス開発者に代わって実現してくれるサービスです。
GoInstantでは、BaaSで一般的に求められるクラウド上でのデータストレージ機能に加え、複数のユーザ間でリアルタイムにデータ同期を行う機能を提供しています。さらにPub/subベースのメッセージ基盤を備えており、デバイスやユーザをまたがった双方向のコミュニケーションに活用できます。
なおGoInstantは、2012年7月にすでにSalesforce.comによって7000万ドルで買収されていますが、同社によって買収されたHerokuと同様に、Salesforceとはサービス的に独立した子会社として運営されている模様です。
使い方
サインアップ
GoInstantには無償利用できる枠(100同時ユーザ、2GBストレージ上限)が用意されているため、サインアップしてすぐ利用を開始することができます。
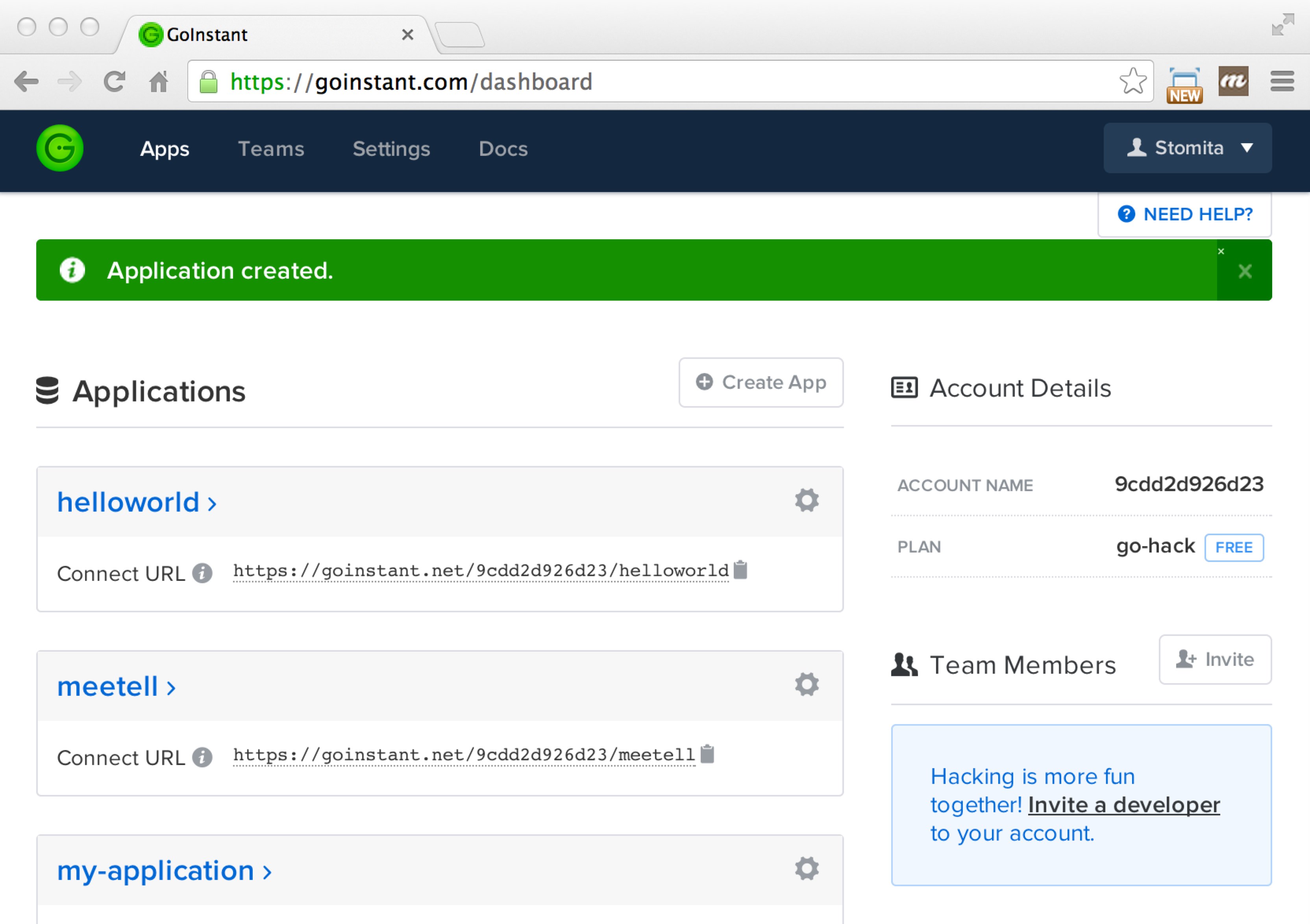
アプリケーション作成
取得したアカウントでGoInstantにログインするとダッシュボード画面が開きます。まずは Create App ボタンを押して新規のアプリケーションを作成します。アプリケーションを作成すると、Connect URL の欄にURLが表示されます。このURLが次のJavaScriptを作成する際に必要になります。
HTMLとJavaScriptコードの記述
続いて GoInstant のサービスを呼び出すためのHTMLファイルとJavaScriptコードを作成します。
<!DOCTYPE html> <html> <head> <script src="//cdn.goinstant.net/v1/platform.min.js"></script> <script src="//ajax.googleapis.com/ajax/libs/jquery/1.10.2/jquery.min.js"></script> <script> var url = "https://goinstant.net/9cdd2d926d23/helloworld"; var conn, room, Messages; $(init); // コネクションの初期化とキーオブジェクトの取得 function init() { goinstant.connect(url) .then(function(result) { conn = result.connection; room = result.rooms[0]; Messages = room.key('messages'); }) .then(queryMessages) .then(watchMessage) .catch(function(err) { console.error(err); }); handleEvents(); } // サーバから最新のメッセージ一覧を取得 function queryMessages() { var yesterday = Date.now() - 24*60*60*1000; return Messages.query({ timestamp: { $gte : yesterday } }, { sort: { timestamp: 'desc' }, limit: 10 }) .execute() .then(function(results) { results = results.reverse(); $.each(results, function(i, result) { appendMessageToList(result.value); }); }); } // テキスト投稿のイベントを処理 function handleEvents() { $("#postBtn").on('click', function() { Messages.add({ text: $("#messageText").val(), timestamp: Date.now() }); }); } // メッセージキーに対するデータ追加の通知をハンドルする function watchMessage() { Messages.on('add', { local: true }, function(message) { appendMessageToList(message); }); } // リストにメッセージを表示追加 function appendMessageToList(message) { var messageListEl = $('#messages'); while (messageListEl.children().size() >= 10) { messageListEl.children(":last-child").remove(); } $('<li>').text(message.text).prependTo(messageListEl); } </script> </head> <body> <input type="text" id="messageText"> <button id="postBtn">Post</button> <ul id="messages"></ul> </body> </html>
以上は、GoInstantが提供するストレージを利用した、テキスト投稿サービスの例です。バックエンドのプログラムを書かなくてもHTML+JavaScriptのみでこのようなサービスが作成できます。
上記のスクリプトでは、ストレージ内のメッセージデータのクエリ及びデータの追加を行っていますが、特に注目していただきたいのは、watchMessage() 内でサーバ側のストレージへのメッセージ追加のイベントを受け取って処理している点です。
ブラウザを2つ立ち上げて同時にページにアクセスすると分かりますが、一方で投稿したテキストは、即座に他方のブラウザに通知されて、新規メッセージがリスト内に表示されます。

特徴
データストレージ
GoInstantでは、ストレージは階層的なツリー構造で提供されており、キーを介して各ノードにアクセスできるようになっています。先程のテキスト統合アプリを例に取ると、メッセージレコードもそれらを格納しているコレクションも、すべて一意のキーが与えられることになります。
階層構造のストレージのルートはルームと呼ばれる単位で管理されています。ルームには接続している参加者のリストが格納されており、ここで参加者を管理したり、メッセージの配信先を制限することができます。
// コレクション var Message = room.key('messages'); // コレクション内のレコード var message1 = Message.key('id-1453ab8c1c4-000'); // ルームからのパスで指定することも可能 // var message1 = room.key('messages/id-1453ab8c1c4-000') /* 1) レコードの内容を取得(コールバック関数での呼び出し)*/ message1.get(function(err, record) { // ... }); /* 2) レコードの内容を取得(Promise形式)*/ message1.get().then(function(record) { // ... }).catch(function(err) { // エラー処理 });
後で述べるように、ルーム及びそれぞれのキーに対して、細かいアクセス制御の設定をすることが可能です。
認証
ソーシャルログイン
GoInstantは、FacebookやTwitterといった外部アイデンティティプロバイダを利用する、いわゆるソーシャルログインに対応しています。現在サポートされているプロバイダは上記の他にGoogle, Salesforce, GitHubなどがあります。
JavaScript開発者は、特に連携のためのやりとりを気にする必要はなく、 connection.loginUrl(providerName) でプロバイダへのログインURLを取得し、画面をリダイレクトするだけで大丈夫です。
なお、連携するプロバイダについては、あらかじめOAuthのclient_idおよびclient_secretなどを管理設定ダッシュボード画面に登録する必要があります。
JSON Web Token によるアサーション
しかしながら、GoInstantがこういった外部のアイデンティティプロバイダを利用したソーシャルログインに対応したのは実はごく最近で、それまではJSON Web Token(JWT)を用いたアサーションを外部アプリケーションに発行してもらい、それを受け取ってユーザを認証していました。現在も引き続きJWTを利用してカスタムで認証を行うこともできます。
GoInstantが他のBaaSと比べて特徴的なのは、自分自身ではユーザ認証のためのレポジトリを持っていない、ということです。多くのBaaSでは自前でユーザレポジトリを管理し、ユーザ名・パスワードなどのログイン機能を持っていたりしますが、GoInstantでは認証結果を外部プロバイダor外部アプリからアサーションという形で受け取るフェデレーションが前提となっています。このため、既に独自のユーザ空間を持っているWebアプリやWebサイトであっても、プラットフォーム間のユーザ管理の違いに頭を悩ませることなく利用できるようになっています。
アクセスコントロール
BaaSにおいては、エンドユーザから直接データストレージへのアクセスを許すことになるため、データのアクセスコントロールを設定できることは最重要です。また、そのアクセスコントロールのポリシーをどれだけ細かい粒度で設定できるか、ということは、そのプラットフォーム上で利用できるアプリケーションの多彩さを決定づけることになります。
GoInstantでは、アクセス主体をユーザおよびグループ単位で指定できるようになっており、対象のリソースはルームはもちろん、それぞれのキーレベルについても指定可能です。許可する操作についてもかなり細かく(read/writeだけでなくget/set/add/removeとそれらのイベントに対するアクセスなど)指定できます。
なお、先にも記載したとおり、GoInstant内にはユーザレポジトリは存在しないため、ユーザIDやグループなどの情報は外部のプロバイダが利用しているものをそのまま利用するか、外部アプリケーションがJWTのアサーションに属性情報として渡してやる形になります (例:GitHubでログインした場合はユーザIDは github:23387 のような形になる)
これらのアクセスコントロール情報を指定するACLは、JSON形式で記述し、管理ダッシュボードから設定することができます。以下はその例のうちの1つです。
{
"$room": {
"#join": { "users": ["*"] },
"shoppingcart": {
"#get": { "groups": ["viewers"] },
"secret": {
"#get" {
"users": ["15"],
"groups": []
}
}
}
},
"#connect": { "users": ["*"] }
}
WebRTC
GoInstantは、今年の初めにWebRTCへの対応を発表しました。
もちろん、WebRTCのバックエンドを提供しているサービスは他にもあります(国内だとSkyway WebRTCなどが有名です)が、リアルタイム・メッセージングに関わるプラットフォームを包括的に提供しようという意志を感じますし、次世代のコミュニケーションインフラとしての地位を狙いつつあるようにも見えます。
GoAngular
GoInstantが提供するリアルタイムデータ同期の仕組みは、双方向データバインディングを提供するJavaScriptフレームワークと大変相性が良いため、AngularJSなどと組み合わせることによって威力を発揮します。GoAngularは、GoInstantをAngularJSで利用するための仕組みです。
まとめ
想定されるターゲット
GoInstantは、他の多くのBaaS(Mobile BaaS = MBaaS などとも呼ばれます)とは異なり、モバイルアプリに特化している、というわけではありません。Webサイト/Webアプリに対してGoInstantの提供するJavaScriptを埋め込むだけでリアルタイム・メッセージングのサービスを即座に利用できることを売りとしています。
さらに言うと、特にiOSやAndroidなどのネイティブアプリ向けのSDKが用意されているわけではなく、現状では想定もされていない様子です。この辺りはすでにiOS向けのSDKなども用意している競合サービスのFirebaseに少々軍配が上がります。
というわけで、新規のモバイルアプリのバックエンドに利用するというよりは、どちらかというとWebサイトやWebサービスは他のPaaS/IaaSなどのクラウド環境で開発・運用を行った上で、リアルタイム関連の機能のみを外出しして利用するようなケースが一番現実味があるでしょうか。本文中で述べたとおり、自前ではユーザレポジトリを持たずに認証連携をデフォルトとするなど、外部サービスとの共存共栄を重視したサービス・アーキテクチャであることは、このような用途に非常に適していると感じます。
また、サーバプログラムを介さなくても静的Webサイトに組み込めるという特性から、S3、GitHub Pagesなどの静的Webホスティングサービスと組み合わせるのも相性が良さそうです。ブログサービスやニュースサイトにウィジットとして埋め込んで、リアルタイム版DISQUS、のような使い方もあるかもしれません。
参考情報:競合サービス
SAML統合でSalesforceからAWSのサービスにアクセスする (3)
こんにちは、@stomita です。
SAMLを使ったSalesforceとAWS S3の連携についての記事書いてますが、どうやらこれで最終回を迎えそうです。
前回は設定ばかりでかなりめんどくさかったと思いますが、重要なところ(SalesforceからSAML連携してS3のAPIの呼び出しまで)はだいたい達成できました。
今回は、アプリケーションとして実際に役に立つように、作成したアプリに少しづつ手を加えていきます。内容はかなりJavaScriptがメインになります。
はじめてこの記事にアクセスされた方は、これまでの記事をぜひご覧ください。
それではどうぞ。
↓